
Iconic Memory
Iconic memory is the most quickly processed form of memory. Information stored in iconic memory is processed automatically, and the information is held there for less than a second.
Iconic memory is the visual sensory memory register pertaining to the visual domain and a fast-decaying store of visual information. It is a component of the visual memory system which also includes visual short-term memory (VSTM) and long-term memory (LTM).
Humans are primarily visual animals. As such, iconic memory is the most extensively studied sensory registerOpens in new window. Information is representned in iconic memory in a form that captures visual stimulation from our retinas, although there are some important differences. The mental representation in iconic memory is called an icon (hence the name iconic memory).
To understand the role that iconic memory plays, we need to understand how much information is held in iconic memory, how long an iconic representation is retained, and how iconic information is used to build up mental representation of the visual world, even though at any moment we only see a small bit of it.
Span and Duration of Iconic Memory
The first two issues addressed here concerning the visual sensory register memory are how much information iconic memory can hold, and how long it can hold it.
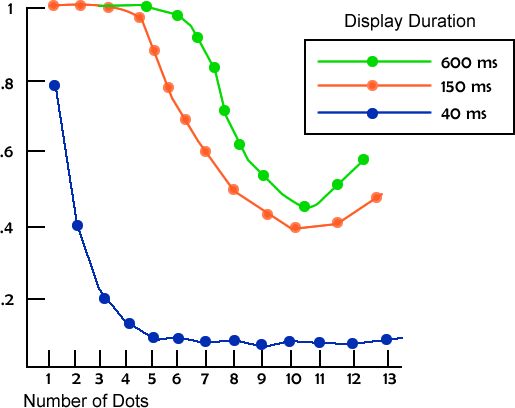 Figure X-1 Span of Apprehension Averaged Across Participants
Figure X-1 Span of Apprehension Averaged Across ParticipantsAdapted from: Averbach, E. (1963). The span of apprehension as a function of exposure duration. Journal of Verbal Learning and Verbal Behavior, 2, 60 – 64 |
In one study, Averbach (1963) presented two people (himself and another) with sets of one to 13 dots for brief periods of time, anywhere from 40 to 600 milliseconds. The task was to say how many dots were in the display. The results are shown in Figure X-1. For the briefest display (40 ms), people were fairly accurate when there was one dot, but they were fairly accurate when there were up to four or five dots, with performance declining gradually after that.
Although there is a large time difference between the second and third condition, the pattern of performance is roughly the same. The additional time did not provide much benefit. Because this study looked at briefly presented displays, it is assessing iconic memory.
From these data it is tempting to conclude that the amount of information held in iconic memory is four or five items. Any more is beyond a person’s capacity. Within that range, people can make an accurate assessment of how many items are present. However, this is an incorrect conclusion.
In a study by Sperling (1960), people were shown brief displays, similar to the Averbach (1963) study. People saw displays of letters instead of dots, and there were always 12 of them (in a 3 x 4 matrix).
The task was to recall as many letters as possible. This display was presented for 50 milliseconds. In the control condition (also called the whole report condition), Sperling had people report as many of the letters as possible. In this case, people were able to name four or five. Again, by itself, this could be interpreted as showing that the number of items in iconic memory is four or five.
However, there was an experimental condition in Sperling’s (1960) study (also called the partial report condition). Here, one of three tones was sounded to indicate which row of the display people should report. A high tone indicated the top row, a medium tone was for the middle row, and a low tone was for the bottom row. Moreover, this tone occurred occurred anywhere from just prior to the display being removed to one second after the display had disappeared.
Sperling used the sum of the performance at each row to estimate how much information was initially available in iconic memory. If people could always report all four items in a cued row, this would indicate that all of the information was represented, but that it decayed quickly.
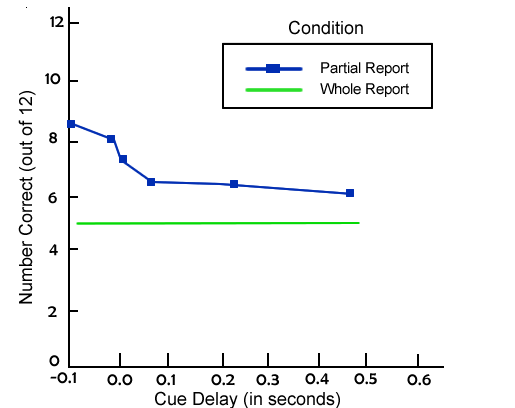 Figure X-2 Availability of Information in Iconic Memory
Figure X-2 Availability of Information in Iconic MemorySource: Sperling, G. (1960). The information available in brief visual presentations, Psychological Monographs: General and Applied, 74(11), 1 – 29 |
Alternatively, if people could report all four items from the top row but very few, if any, from the other rows, this would suggest that iconic memory can hold only few items. The results of this study are shown in Figure X-2.
Performance was near ceiling (very close to perfect) when the tone cue was presented at the time the displays was removed. However, as the amount of time increased before the tone, there was a decline in performance. Nearing the quarter-second mark (250 milliseconds), people approached performance in the whole report condition. This indicates that a large amount of information is held in iconic memory—perhaps just about anything entering the visual system. However, iconic memory has a very brief duration.
By about a quarter-second, nearly everything that was initially in iconic memory has decayed away. This decay is deterministic, not random, suggesting some influence of higher-order processes (Gold, Murray, Sekuler, Bennett, & Sekuler, 2005). Anything that is left was presumably transferred from iconic memory into short-term memory before it was lost.
Anorthoscopic Perception
The effects of iconic memory can be observed in the distortions it produces. For example, a lightning strike appears to last longer than it actually does because we hold onto a memory of it. Another illustration is anorthoscopic perception, or the seeing-more-than-is-there phenomenon (Parks, 1965). This can be demonstrated by passing a picture behind a slit, as shown in Figure X-3. If the figure is moved at a reasonably fast speed (e.g., 250 – 300 ms), people report seeing more of the figure than there actually is at any one point in time. This occurs because people are integrating information in iconic memory to reconstruct the shape of the object.
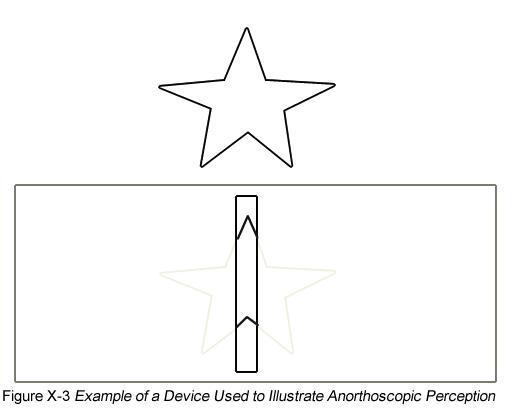 Figure X-3 Adapted from: Haber, R. N., & Nathanson, L. S. (1968). Post-retinal storage? Some further observations on Parks’ camel as seem through the eye of a needle. Perception & Psychophysics, 3, 349 – 355
Figure X-3 Adapted from: Haber, R. N., & Nathanson, L. S. (1968). Post-retinal storage? Some further observations on Parks’ camel as seem through the eye of a needle. Perception & Psychophysics, 3, 349 – 355 |
What also happens during anorthoscopic perception is that the iconic memory is compressed to accommodate all that was seen in a small region of space (McCloskey & Watkins, 1978). An example of this compression is shown in Figure X-4.

|
Furthermore, the faster the objects are moved behind the slit, the more compression there is (Haber & Nathanson, 1968). This is not the result of a retinal afterimage. If lots of visual information were presented to the same place on the retina, and people were using an afterimage of that, then it would all be jumbled into the same space on the retina and a perceptual blob would result. Instead, there is an active construction based on a memory of what was recently seen.
There is a clear evolutionary advantage to having such a sensory register. Suppose you try to identify an object as it moves behind a cluster of branches. If you can quickly integrate the bits and pieces you are able to see, you can identify the creature more quickly. Is it lunch or a predator?
Trans-Saccadic Memory
We do not view the world in one glance. Instead, we must move our eyes, head, and body to scan our surroundings. In doing so, we view different parts of the world and then integrate them to build a complete mental picture. A typical eye movement is called a saccade. When our eyes land on some point in space, it is called a fixation. Fixations typically last around 300 milliseconds and saccadic eye movements typically take about 30 ms to execute.
Moreover, we mostly process information during the fixations. This characteristic of vision is important because it places demands on iconic memory. We need to integrate information across saccades to build up a picture of the world. There needs to be a trans-saccadic memory (see, e.g., Irwin, 1996) aspect of iconic memory to do this. There are a number of ideas about how this is done.
One idea was that trans-saccadic memory uses retinal coordinates, the position of an image on the retinas of your eyes. This makes sense in that iconic memory is a visual memory and the eyes provide the initial basis for this kind of information. However, this is incorrect. For example, suppose people are presented with two displays composed of portions of a 3 x 3 grid of eight dot locations. If the two grids were overlaid on top of one another, one could pick out the location of a missing ninth dot. This is easy to do when the two grids are presented in the same position and people do not have to move their eyes.
The process of using this idea to test trans-saccadic memory is shown in the left column of Figure X-5. The first display appears where people are currently looking. Then a cross appears in the periphery indicating where people should look next.
 Figure X-5 Testing Retinally Based, Spatially Based, and Object-Based Ideas About Trans-Saccadic Memory
Figure X-5 Testing Retinally Based, Spatially Based, and Object-Based Ideas About Trans-Saccadic MemoryAdapted from: Irwin, D. E. Brown, J. S., & Sun, J. S. (1988). Visual masking and visual integration across saccadic eye movements. Journal of Experimental Psychology: General, 117, 276 – 287. |
As people move their eyes to the new location, the first display is erased, and a second is presented where the eyes have moved to. This second display overlaps the first in retinal coordinates (that is, the same place on a person’s eye). Under these conditions, people are not able to integrate these two displays to find the missing dot location. Thus, where images fall on the eyes does trans-saccadic memory use spatial information—that is, where things are in space? This makes sense in that people need to know how the world is structured beyond themselves.
So, it could be that iconic memory uses information about where things are in space to build up an understanding of the world, similar to the way you could build up a larger picture by overlapping photographs taken from different positions. A similar procedure used to test the idea of retinally based integration can be used to test the idea of retinally based integration can be used to test this idea. This is shown in the middle column of Figure X-5, where the two dot patients are in the same spatial location even though the eyes are in motion. However, this does not work either. People cannot perform well even though two images are in the same spatial location (Irwin, Yantis, & Jonides, 1983).
Instead, what appears to be going on is that trans-saccadic memory uses representations of objects, called object files (Kahneman, Triesman, and Gibbs, 1992). That is, individual objects or entities serve as the basis for how we assemble our mental understanding of the visual world. Trans-saccadic memory does this by keeping track of basic characteristics of an object. Evidence for this comes from studies in which people are able to detect that something has been changed after an eye movement (Henderson & Anes, 1994). For example, in the right column of Figure X-5, the task would require a response to indicate whether the dot pattern changed from one display to the next. This is a task that people can do quite readily. Moreover, change detection is more likely to occur when the entity is at the focus of attention rather than in the background. This suggests that although we subjectively experience the world as stable and full of detail, this impression relies in part on our memories to fill in the gaps with what we have seen before, or with what long-term memory assumes should be there.
Although trans-saccadic memory seems fairly simple, it can have important influences on more complex processing. That is, you can’t do some kinds of thinking such as an inverted sign, this takes longer if they have to concurrently make an eye movement (Irwin & Brockmole, 2000).
The execution of an eye movement and active operation of trans-saccadic memory puts other memory processes on hold while the eyes are doing their thing. This may be because the same part of memory is needed to do both, and these two very simple cognigive operations, moving the eyes and mentally turning something, use the same underlying machinery.
Change Blindness
The lack of accurate detail in iconic memory has interesting consequences. For example, there are often errors in feature films that go unnoticed by most audience members, such as objects appearing and disappearing across cuts, clothes changing, and so on. These are called continuity errors.
In a set of studies, people saw films in which objects changed across cuts. For example, dinner plates might change from red to white. However, people were very poor at detecting these changes and only did so less than 2% of the time (Levin & Simons, 1997).
In one study, people watched films in which one actor was changed across film cuts (the two people were of the same gender and ethnicity). Only 33% of the people noticed the change (Levin & Simons, 1997).
In another example, an experimenter asked an individual (the subject) on the Cornell University campus for directions. While giving directions, two people passed between them carrying a door, thus blocking the subject’s view of the experimenter. At this time, a second experimenter switched places with the first. After the door had passed, many people continued giving directions even though they were now talking to a different person. Only about 50% of the people noticed the switch (Simons & Levin, 1998).
Visual memory reflects our expectations. For briefly presented scenes, people are more likely to detect a change in an object if it belongs in the scene (e.g., a blender in a kitchen) than if does not (e.g., a live chicken in a kitchen) (Hollingworth & Henderson, 2003). This prior knowledge and expectation includes social constraints. In person-change experiments, college students were more likely to detect a person-switch when the experimenters were dressed like students than when they were dressed like construction workers. Students are in the same social group as the people being tested, but construction workers are not, so less attention is paid to them.
- Averbach, E. (1963). The span of apprehension as a function of exposure duration. Journal of Verbal Learning and Verbal Behavior, 2, 60 – 64.
- Sperling, G. (1960). The information available in brief visual presentations, Psychological Monographs: General and Applied, 74(11), 1 – 29.
- Haber, R. N., & Nathanson, L. S. (1968). Post-retinal storage? Some further observations on Parks’ camel as seem through the eye of a needle. Perception & Psychophysics, 3, 349 – 355.
- Irwin, D. E. Brown, J. S., & Sun, J. S. (1988). Visual masking and visual integration across saccadic eye movements. Journal of Experimental Psychology: General, 117, 276 – 287.
